


Introduction
Infinite scroll is a common interaction pattern on the web today. To save bandwidth and server resources, a webpage only loads a subset of items in a collection initially. As the user scrolls through the collection (e.g., a photo gallery), the webpage loads more items in the background and appends them to the visible collection that the user sees. For ordered collections that are static, each subsequent “page” of items can be cached in-memory since the page boundaries are known ahead of time.
In contrast, dynamic collections pose a challenge to data consistency when using infinite scroll because the underlying order and make-up of items can change while the user scrolls the page. In the extreme, each visitor might see a different logical collection, which creates a trade-off between caching duplicate pages across visitors and displaying a correct (or, at least, coherent) collection.
This article describes this problem in more detail, highlights the trade-offs, and presents a few approaches for achieving consistency.
Problem Statement
Imagine a popular content aggregation site that
displays items in a grid
sorted chronologically in reverse
based on the item’s creation or updated time.
When items are updated after their initial creation,
they are moved back to the top of the collection,
and all items have a last_updated_timestamp property.
Further, suppose the collection of all items
is very large and new items are added frequently.
To avoid loading all items on every page load,
the webpage instead fetches only a subset of items initially.
As the user scrolls down the page,
the page loads additional batches of items and
appends them to the visible collection in the UI.
Thus, the newest items are loaded first,
followed by progressively older items.
The webpage loads batches of items
with a GET request to the site’s REST API,
and the endpoint returns items by querying a database.
Because new items can be created at any time, and existing items can be updated at any time, the naive approach of blindly appending newly-fetched items to the end of the gallery could end up displaying the same item twice if its position in the ordered list of items changed since the initial page load.
Requirements
The site owners have a few requirements for the user experience and behavior of the page.
-
The page cannot immediately load all items for every visitor due to the computation and network burden on both server and client. Also, not every visitor will scroll to the end, so loading all items would be unnecessary in those cases.
-
The page can’t show duplicate items.
-
The front-end UI can’t reorder items that are already displayed. Once items are visible they must stay in their position.
-
Nice-to-Have: items won’t be omitted from the displayed collection. It’s better to show an item in a “stale” position than to not show it at all. But per 2. above, duplicate items (e.g., an item in its old and new position) are not allowed.
Trade-offs
The requirements forbid loading all items, but it’s worth it to explore what costs this approach would incur and what we’ll have to trade-off to meet the requirement.
Let’s assume that an item displayed on the page is not directly equivalent to an item stored in a DB. For example, maybe the raw properties of the item are stored in one location, but analytics or other metadata reside in a different DB. This means the server has to materialize items in-memory before it returns them to the client. Additionally, let’s assume the materialized version of an item is 1KB or larger. Thus, by not immediately requesting thousands of items, for example, we’re saving the server computational costs as well as client-perceived network delay receiving the items.
The trade-off in exchange for that efficiency is obviously the complexity of paging through items when the “version” of the collection can change between pages.
To understand why the duplicate item problem arises when fetching subsequent pages, consider a collection of items that changes over time as depicted in the following figure.
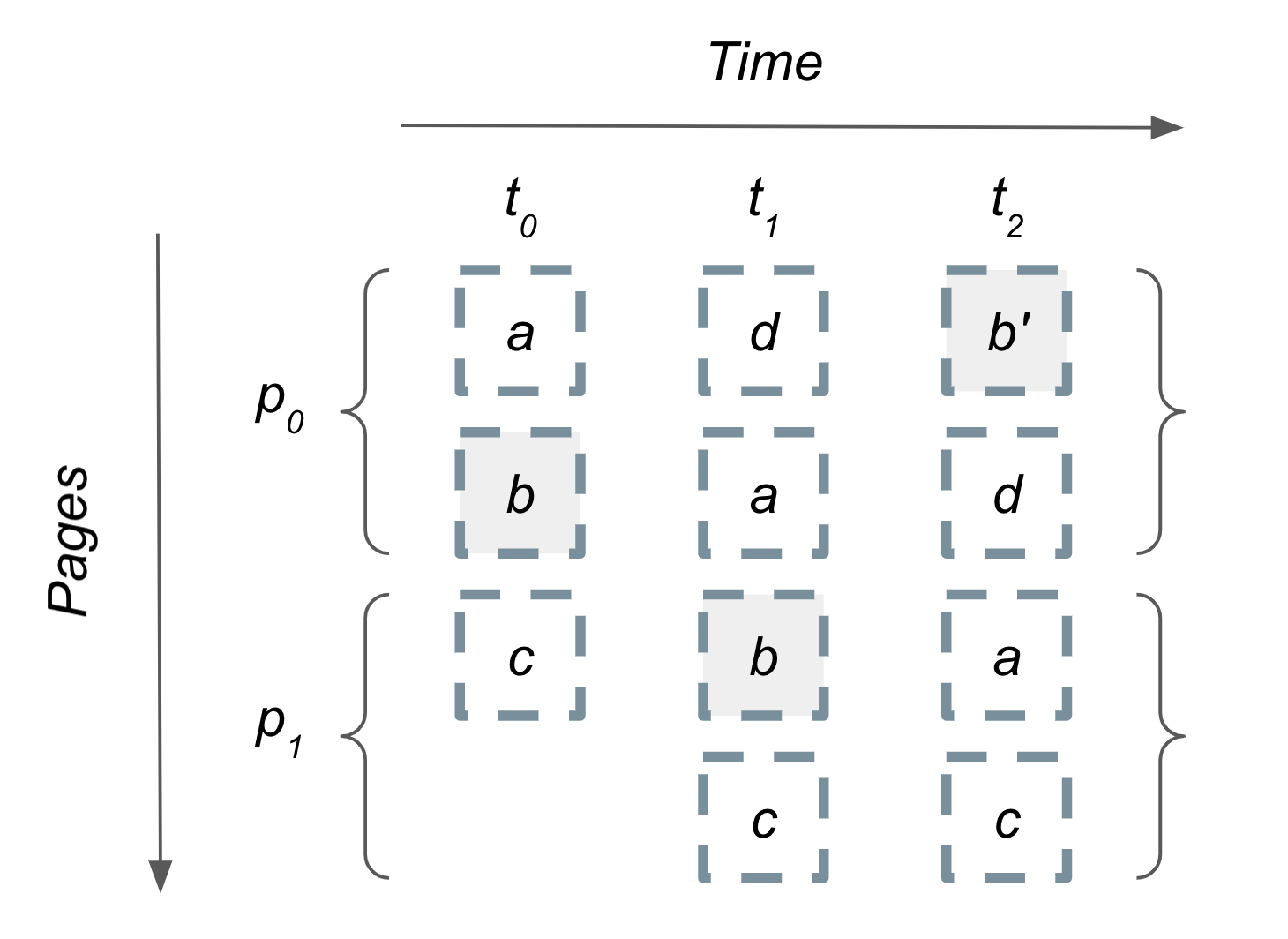
At the initial time, t₀, the collection consists of three ordered items, a, b and c. Each page of items contains up to two items. A user will fetch the first page of items, a and b, and then later fetch the second page of items, which only has c at this time.
Then, the collection changes at time t₁ and now includes item d as the first item. All other items are shifted “down” in the collection. A user loading the site at this time will see items d and a in the first page, and then items b and c in the second page. However, a user who began their session at t₀ and later fetches their second page at t₁ will see a duplicate item b in the second page’s results.
At time t₂, the b item is updated and moved to the first position in the collection. This pushes d, a and c down by one position. Again, naively fetching a page of items and appending the items will lead to a duplicate a and/or b depending on when the session began.
Requirement 3 prevents us from collecting all items
in-memory at the client and reordering them
based on their last_updated_timestamp.
Together, these requirements suggest that we’ll need a bookmark or anchor to keep track of the client’s position in the collection as it fetches pages. The bookmark can convey to the server which items the user has already seen so that the server can omit them in its results, or it can communicate a historical version of the collection from which the server should pull items. This latter approach would require the server to maintain (or recreate) historical versions of the collection somewhere, and might increase costs or complexity.
Other considerations:
-
What is the size of the full collection? This was mentioned at the outset to be “very large”. But in a real-world scenario, we’d want to quantify the full collection size, as this would inform whether the naive solution of fetching all items is feasible.
-
What is the frequency of items being added or updated? For example, if items change once per year and the average active sessions per second is low, then the chances of a duplicate item might be acceptably low to page through items without a bookmark.
-
How long should a user session be “supported”? For example, if a user fetches a single page of items and leaves the site open for days, what items should be loaded when they finally scroll? Usually, a reasonable default will work, but certain applications might handle this specially.
Design
In order to design our solution,
we need to specify a few system components.
The webpage consists of static assets,
which load items from our REST API’s
GET /items endpoint.
The endpoint accepts query parameters
for offset and limit and other filters.
The server queries an internal database for “raw” items,
materializes complete items by querying other services,
and then returns JSON items to the webpage.
Later iterations of the design
will cache materialized items,
and allow the server to skip the database query
for requests that it has already seen.
First-cut solution
The primary requirement informing our first solution
is that we cannot return duplicate items.
One way to meet this requirement is
to have the front-end webpage produce a timestamp
at the time of page load, and
use this bookmark as a filter for only items
whose last_updated_timestamp is less than or equal to
this timestamp.
Pseudocode for the endpoint might look like this:
|
|
This avoids duplicates because each visitor (i.e., page load) will establish their own filter for items, and the filter will exclude any item that is updated after the page was loaded. There are at least two drawbacks to this approach:
- Every visitor establishes their own filter at the millisecond resolution (for example), so it’s difficult to benefit from caching popular pages (e.g., the first page) that most visitors will need.
- If an item is updated after it was returned, then all subsequent items are shifted and this causes items to be omitted completely. The omission of an item is allowed, per our requirements, but we’d like to avoid it if possible.
Version 2
A small modification to our initial implementation
allows us to begin to address the first drawback and
improve the overlap of pages across visitors.
Instead of each visitor establishing
their own timestamp bookmark,
they can fetch the first page of items normally and
then use the last_updated_timestamp of the first item itself
as the bookmark filter for future queries.
|
|
While this approach does not actually use a cache, it causes all requests for pages after the first to share the same timestamp bookmark. This means that until the collection is updated again, all visitors will use the same queries for items.
Version 3
In our final version we introduce the cache.
Generally, the cache is warranted when the
database.query(...) and/or
materialize(...) operations are expensive
in terms of latency or computation.
Our latest pseudocode looks like the following:
|
|
Along with caching requested pages,
it’s usually necessary to evict stale pages
when the underlying collection changes.
A simple approach to caching and evicting is
to cache the first page (at offset=0) and
evict it whenever any item is added or updated
in the collection.
This ensures that whenever the collection changes,
a future visitor will see the newest items and
establish a new bookmark for subsequent pages.
As visitors load more pages against
this particular version of the collection,
the cache will fill up with these materialized pages.
The cache hit rate will continue to increase
until the next update to the collection.
Discussion
As mentioned in the first version of our solution, using the time-based filter means that any time an item is updated and excluded from the collection, some other item is shifted into its position in the results and potentially omitted from the results during paging. The requirements state that this is preferred to showing duplicate items, so it’s okay in our scenario. But different approaches might prioritize not omitting items.
The determining factor in the rate of omissions is the ratio of (visitors) : (collection updates). If many visitors see the same “version” of a collection, then they will cache on the same pages and omissions will be lower. If the rate of updates to the collection is high, then visitors are more likely to see different versions and the cached page hit rate will be lower, which increases the chances of an omission. (Omissions only occur for visitors who have already loaded the first page when a collection update occurs.)
Version 3 mentions evictions as a means of ensuring the newest items are returned to any new visitor after the update. Another consideration related to evictions is what to do if an item is deleted from the collection. In the scheme above, it’s possible that the server will return a deleted item in a cached page. A simple approach is to evict all pages from the cache when an item is deleted, but this will reduce cache hit rate for every request, rather than only the pages with the item. Given that the only visitors who will still see the deleted item are those visitors who started their session before the item was deleted, it might be reasonable to not evict at all. This is the behavior in Version 3 above.
Conclusion
This article explores some challenges and trade-offs in providing a stable ordering of a dynamic collection of items as informed by the common infinite scroll web behavior. Informed by real business requirements, including caching, we hope you found the approaches to be straightforward and illustrative. If you like thinking about these types of problems or would like to discuss further, shoot us a note at [email protected] We’d love to hear from you!